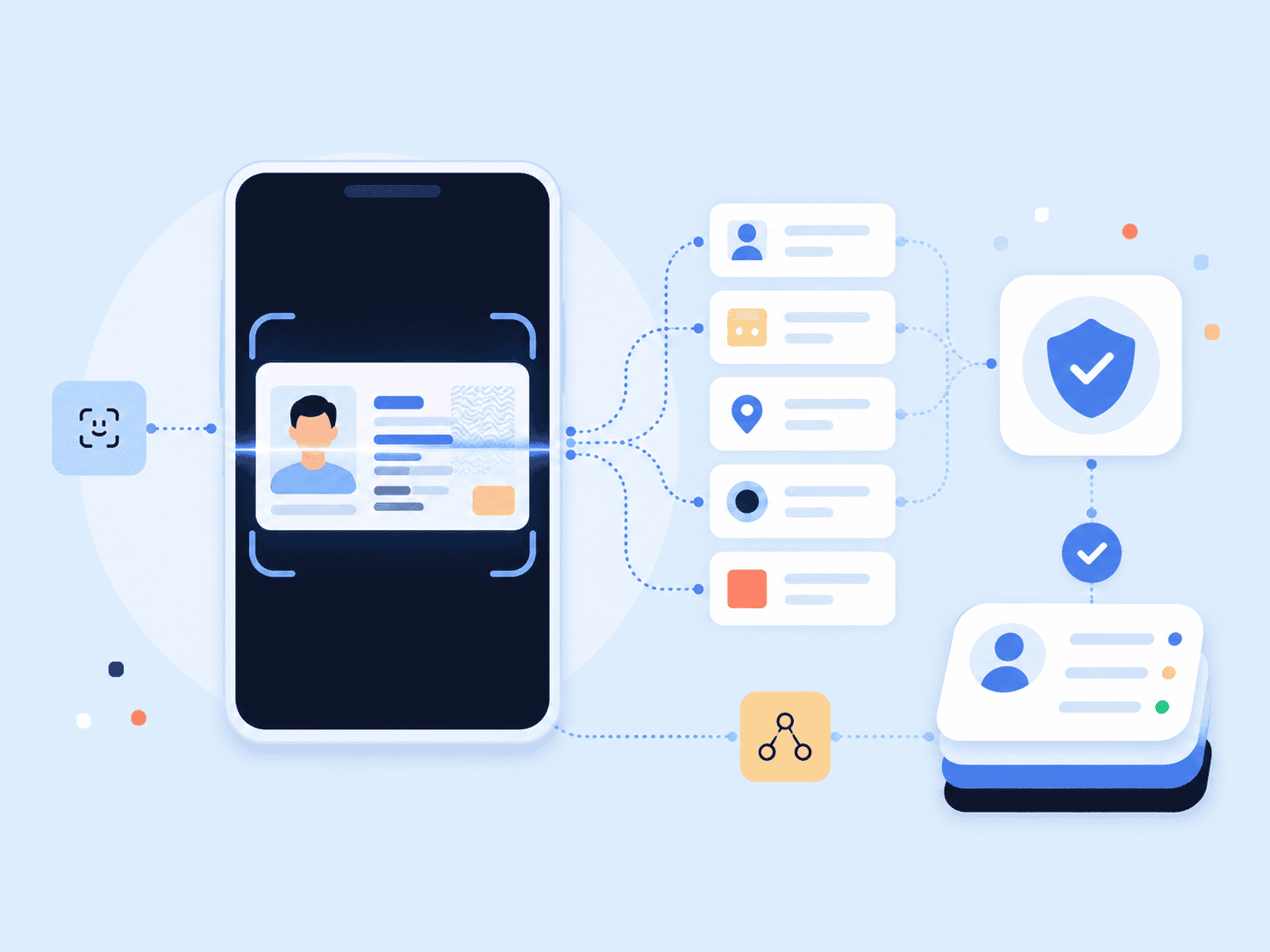
A photo of an ID can look perfectly readable to a person and still fail inside a verification workflow. Glare hides the date of birth. A cropped edge cuts off one character. A font on a passport behaves differently from a driver’s license. That’s where OCR (Optical Character Recognition) matters. It converts text from images, scans, PDFs, receipts, invoices, and paper documents into machine-readable text that software can search, validate, and act on.
This guide focuses on one specific angle: how OCR works inside identity verification and document processing workflows where speed, accuracy, privacy, and fraud prevention all matter.
Key Takeaways
- OCR converts text from images, scans, PDF documents, TIFF files, receipts, invoices, and IDs into editable or searchable data.
- OCR accuracy depends heavily on image quality, capture guidance, document type, font, language, and validation after extraction.
- Modern OCR systems often combine computer vision, machine learning, pattern recognition, and natural language processing.
- Identity workflows need more than basic text extraction. They need document checks, liveness detection, data validation, and privacy controls.
- The strongest OCR workflows start before extraction, with better capture, cropping, glare control, and confidence scoring.
What OCR Does in Document Workflows
OCR is the technology that helps software recognize text inside a visual file. That visual file might be a scanned document, a PDF, a receipt photo, an invoice, a passport image, a driver’s license, or a TIFF file from a scanner. Instead of storing the file as a flat image, OCR software can extract text so it becomes searchable, editable, and usable in automation.
A simple OCR tool might only read printed text from a clean scan. A more advanced OCR engine can detect document layout, separate fields, recognize text at different angles, and return structured output such as name, date of birth, address, document number, and expiration date. Google’s Cloud Vision documentation, for example, separates general text detection from document text detection, with the latter optimized for dense documents and returning page, block, paragraph, word, and break information through its OCR capabilities in the Cloud Vision API.
That distinction matters. Extracting one line from a street sign is not the same as reading a government ID, a bank statement, or a multi-page PDF document. In business workflows, OCR processing usually has to answer three questions at once:
| Workflow question | Why it matters |
| What text is present? | The OCR system needs to recognize text accurately. |
| Where does the text belong? | Extracted text must map to the right field, such as name or date of birth. |
| Can the data be trusted? | The workflow may need validation, fraud checks, or manual review. |
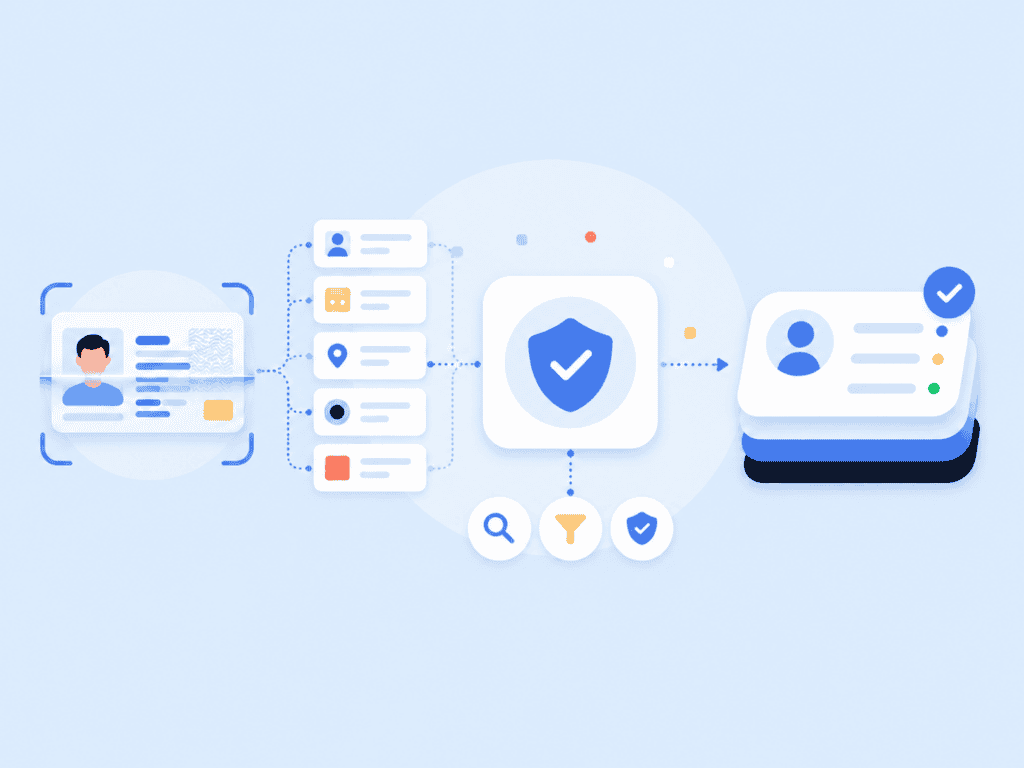
For identity verification, OCR is usually one part of a larger process. A document verification flow may capture the document, crop the image, extract text, check the barcode, compare the selfie to the document portrait, and validate data against trusted sources. That’s why OCR should not be evaluated only by whether it can “read text.” It should be judged by whether it improves the full workflow.
For example, document verification often requires accurate data extraction from government-issued IDs along with document authenticity checks, portrait matching, and third-party validation. OCR helps with the extraction step, but the verification decision depends on everything around it.
How OCR (Optical Character Recognition) Works
OCR (Optical Character Recognition) usually starts with image preparation. Before a system can recognize text, it has to clean up the input. That may include correcting skew, reducing noise, increasing contrast, detecting edges, cropping the document, and separating text from the background. A scanner might produce a cleaner image than a phone camera, but phone capture can work well when the workflow gives users real-time guidance.
After preprocessing, the OCR engine identifies regions likely to contain text. Older OCR technologies relied more heavily on pattern recognition and character templates. They looked for shapes that matched known letters, numbers, or symbols. That worked well for consistent printed fonts, but it struggled with unusual layouts, low-quality scans, handwriting, and distorted images.
Modern OCR uses machine learning and neural network models to recognize characters, words, and layout patterns with more flexibility. Instead of treating every glyph as one isolated character at a time, many advanced OCR systems use surrounding context. This is where optical word recognition, intelligent word recognition, and natural language processing can help. If an OCR output reads “J0HN” in a name field, the surrounding field type and expected character pattern can help flag the zero as suspicious.
A practical identity workflow often looks like this:
- Capture: The user scans or photographs an ID, receipt, invoice, or other document.
- Quality check: The system checks blur, glare, resolution, angle, cropping, and whether the full document is visible.
- Document detection: Computer vision locates the document boundary and key regions.
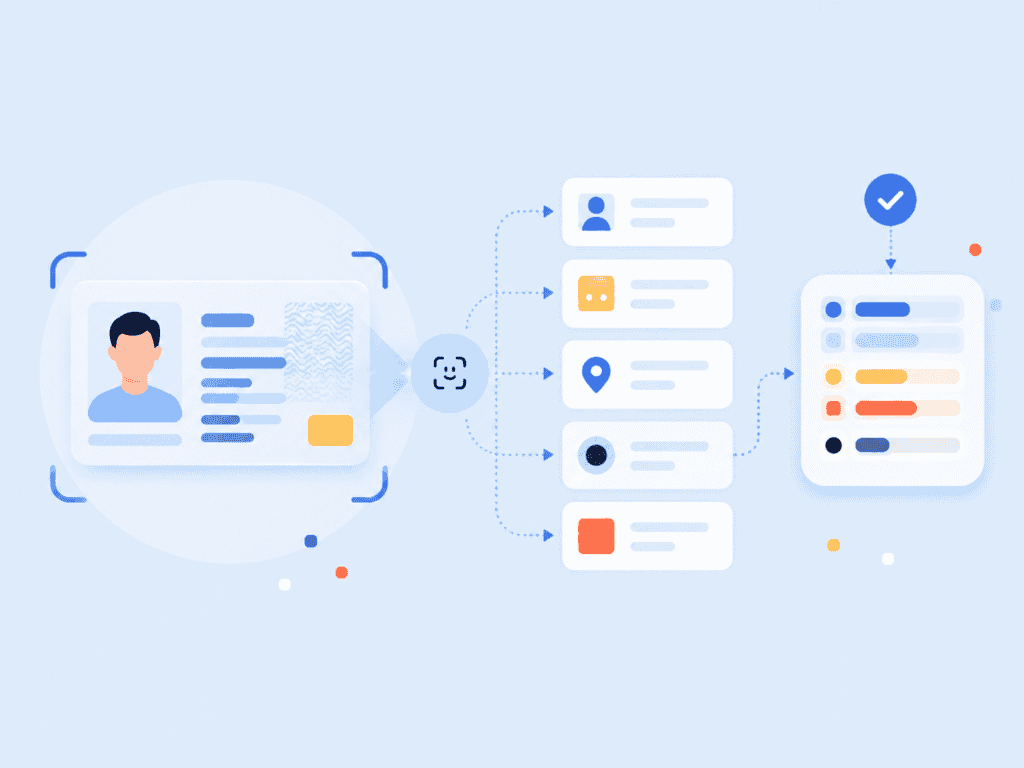
- Text recognition: The OCR engine extracts machine-readable text from the image.
- Field mapping: The output is assigned to fields such as first name, date of birth, document number, address, or expiration date.
- Validation: The system checks format, consistency, barcode data, and, where appropriate, trusted records.
- Decisioning: The workflow returns approved, failed, or manual review status.
Here’s the practitioner detail that often gets missed: OCR accuracy is not only an extraction problem. It’s a capture problem. If the first image is poor, the OCR system may still return text, but the confidence score may be low or the field mapping may be wrong.
A strong workflow catches bad inputs before OCR runs. For example, an ID capture screen can reject images where the document edge is cut off, the barcode is unreadable, or glare crosses the date of birth. That one step can reduce repeated failed attempts more than simply swapping one OCR API for another.
Where OCR Accuracy Breaks Down
OCR errors often come from small issues that look harmless at first. A slightly tilted PDF scan might still be readable to a person, but the OCR output could split one line into two fields. A receipt printed on thermal paper may fade enough to confuse totals and dates. A handwritten form might require intelligent character recognition rather than simple OCR text recognition.
Some of the most common failure points include:
| OCR challenge | What can go wrong | Better workflow response |
| Glare on an ID | Date of birth or document number is partially hidden | Prompt the user to retake the image before extraction |
| Low resolution | Characters blur together | Set minimum camera or scan quality thresholds |
| Cropped edges | One character or field is missing | Detect document boundaries before accepting capture |
| Unusual fonts | OCR output misreads similar characters | Use field-specific validation rules |
| Handwriting | Printed OCR models may fail | Use intelligent character recognition where needed |
| Dense PDF documents | Layout is misread | Use document OCR optimized for structured pages |
| Multi-page PDF files | Pages may process out of order | Preserve page order and metadata |
| Poor contrast | Text blends into background | Apply preprocessing before extraction |
This is why OCR accuracy should be measured field by field, not only by the total percentage of recognized characters. In an invoice workflow, a wrong comma in a description may not matter much. A wrong digit in the total amount does. In an identity workflow, one wrong character in a document number, date of birth, or expiration date can trigger a failed verification or a false manual review.
NIST has studied OCR and handprint recognition for decades, including document image understanding and form-based handprint recognition systems used as reference points for OCR evaluation. Its historical work on optical character recognition shows why OCR has long been tied to form processing, tax modernization, census work, and large-scale document handling.
For modern teams, the lesson is straightforward: don’t treat OCR output as automatically correct. Treat it as a structured prediction that needs confidence scoring, business rules, and human review paths for edge cases.
OCR Use Cases for Identity, Finance, and Operations
OCR use cases vary widely, but most fall into one of two groups: making documents searchable or turning document data into automated actions.
A searchable PDF is a simple example. A scanned contract might look like a normal PDF, but without OCR, the text inside may not be searchable or editable. Applying OCR can convert the scan into a searchable PDF, making it easier to find names, dates, clauses, and invoice numbers later.
In operational workflows, OCR does more than improve search. It reduces manual data entry. A finance team might use OCR software to extract vendor names, invoice totals, tax amounts, and due dates from PDF invoices. A logistics team might use OCR scans to read shipping labels. A healthcare intake workflow might extract text from insurance cards or referral documents, then route the data for review.
For identity and age-related workflows, OCR can support:
- Extracting name, date of birth, and document number from a photo ID
- Reading barcode or MRZ data when available
- Comparing front-of-card and back-of-card information
- Checking whether document data matches what the user submitted
- Triggering liveness detection when a selfie is needed
- Routing low-confidence captures to review
A practical example: suppose a user signs up for a regulated service and uploads a driver’s license. The OCR engine extracts the date of birth, expiration date, license number, and address. The workflow then compares the extracted date of birth against the user-entered date of birth. If they match and the document passes quality checks, the system can continue. If the OCR output has low confidence or the document is expired, the workflow can ask for a recapture or route the case for review.
This is where OCR connects directly to identity assurance. A KYC process may include document verification, biometric authentication, database checks, and risk scoring. A KYC API workflow can help automate these checks so teams aren’t manually reviewing every scanned document, ID image, or customer submission.
OCR also pairs with other AI capabilities. Computer vision can detect the document and assess image quality. Machine learning can classify the document type. Natural language processing can help interpret extracted text. Generative AI can help summarize or normalize extracted content in some document processing workflows, though regulated use cases still need strong guardrails, auditability, and validation.
How to Choose an OCR Workflow
Choosing OCR software is not only a product comparison. It’s a workflow design decision.
Start by defining the documents you need to process. OCR for clean PDF files is different from OCR for mobile ID capture. OCR for invoices is different from OCR for handwritten forms. OCR for receipts is different from OCR for passports. The document type affects the OCR engine, capture rules, validation logic, and review process.
A useful evaluation checklist looks like this:
| Evaluation area | Questions to ask |
| Input types | Do you need PDF, TIFF, JPEG, PNG, scanned image, or camera capture support? |
| Text type | Is the text printed, handwritten, mixed, or machine-readable from barcode/MRZ? |
| Output format | Do you need plain text, JSON, searchable PDF, annotated PDF, or field-level extraction? |
| Accuracy controls | Does the OCR system return confidence scores by field? |
| Workflow fit | Can the OCR API connect to your onboarding, data entry, or document processing flow? |
| Privacy | Where are images processed, stored, and deleted? |
| Review process | What happens when confidence is low or data conflicts? |
| Scale | Can the system handle peak volume without slowing onboarding? |
Privacy deserves special attention. Many OCR systems send the image file to a cloud service for processing. That may be acceptable for some use cases, but identity documents and biometric workflows carry higher sensitivity. Teams should know whether images, extracted text, and metadata are stored, transmitted, logged, or reused.
For biometric and identity workflows, OCR often sits beside liveness detection and face matching. On-device liveness detection can help confirm that a real person is present while reducing the need to transmit sensitive images for processing.
Developers should also evaluate API security. If OCR or verification workflows rely on an API, credentials should never be exposed in client-side code. PrivateID’s API documentation notes that API calls use headers such as x_api_key, clientID, and clientSecret, with confidential secrets stored securely and not exposed in client-side code through API authentication and access control.
A simple technical pattern might look like this:
Client device
→ capture image
→ run local quality checks
→ extract required fields or send approved data only
→ server validates session and business rules
→ verification result is returned
That pattern is not right for every OCR use case, but it shows the principle: collect only what you need, validate early, and avoid moving sensitive files around unless there’s a clear reason.
A Better OCR Workflow Starts at Capture
The best OCR workflow is not the one that reads bad images slightly better. It’s the one that prevents bad images from entering the pipeline in the first place.
For ID checks, that means guiding the user while they capture the document. Show whether the ID is fully inside the frame. Check for blur. Detect glare before the user submits. Confirm that the back of the ID was captured when required. If the workflow needs a selfie, use liveness detection at the point where it adds security without adding unnecessary friction.
For back-office OCR use cases, the same principle applies in a different way. Standardize scanner settings. Require searchable PDF output where possible. Keep document naming consistent. Use separate workflows for invoices, receipts, forms, and handwritten notes instead of forcing every file through one generic OCR tool.
Here’s a useful rule from real implementation work: separate “readability” from “trust.” OCR can tell you what text appears in an image. It cannot, by itself, prove that the document is genuine, that the person submitting it owns it, or that the extracted data matches trusted records. That requires verification logic around the OCR output.
The strongest workflow combines:
- Better capture guidance
- OCR text recognition
- Field-level confidence scoring
- Document authenticity checks
- Format and consistency validation
- Liveness or biometric checks where needed
- Clear review paths for uncertain cases
OCR is valuable because it removes manual typing and speeds up document workflows. It becomes much more valuable when it’s designed as part of a complete verification process, not a standalone extraction step.
FAQs
What is OCR in simple terms?
OCR is a technology that helps software read text from images. It can extract text from scanned documents, PDFs, receipts, invoices, ID cards, and photos so the content becomes searchable, editable, or usable in automation.
What is the difference between OCR and text recognition?
Text recognition is the broader task of detecting and reading text from visual content. OCR is the common term for converting printed or handwritten text from images or scans into machine-readable text. In many business tools, the terms are used almost interchangeably.
Can OCR read handwriting?
Some OCR systems can read handwriting, but accuracy depends on the handwriting style, image quality, and model used. Handwritten forms often require intelligent character recognition or intelligent word recognition rather than simple printed-text OCR.
Can OCR convert a scanned PDF into editable text?
Yes. OCR can convert a scanned PDF into searchable or editable text, depending on the software and output format. Some tools create a searchable PDF layer, while others export the extracted text into formats such as DOCX, TXT, JSON, or structured fields.
What makes OCR inaccurate?
OCR accuracy drops when images are blurry, cropped, tilted, low contrast, handwritten, or affected by glare. Accuracy can also suffer when the font is unusual, the scan resolution is poor, or the document layout is dense and complex.
Is an OCR API better than free OCR software?
An OCR API is usually better for automated workflows because it can connect directly to apps, onboarding systems, document processing tools, or data pipelines. Free OCR software may be fine for occasional files, but production workflows often need structured output, confidence scores, security controls, and reliable scaling.
How does OCR help identity verification?
OCR helps identity verification by extracting text from IDs, passports, and other documents. The extracted data can then be checked against user-entered information, document rules, barcode data, third-party records, or biometric steps such as selfie-to-ID matching and liveness detection.